
Flash-moe runs a 400-billion parameter model on a MacBook Pro by streaming weights from SSD. It turns a server-rack problem into a local one with pure C and Metal shaders. The engine streams Qwen3.5-397B-A17B from disk at 4.4 tokens per second. It achieves production-quality output including tool calling on consumer hardware. This breakthrough democratizes massive model inference for developers.
Flash-moe solves extreme memory requirements for large language models. It streams 209GB model weights from SSD through a custom Metal compute pipeline. The project was built in 24 hours with Claude Code autonomously running experiments. Developers gain access to 397B parameter models without server racks.
Project Repository
Project link:
https://github.com/danveloper/flash-moe
How It Works
Flash-moe exploits the memory hierarchy of Apple Silicon Macs. Instead of loading the entire model into RAM, it swaps MoE layers from disk as needed. The Metal compute pipeline uses hand-tuned shaders for maximum GPU utilization. This approach reduces latency and memory footprint compared to Python frameworks.
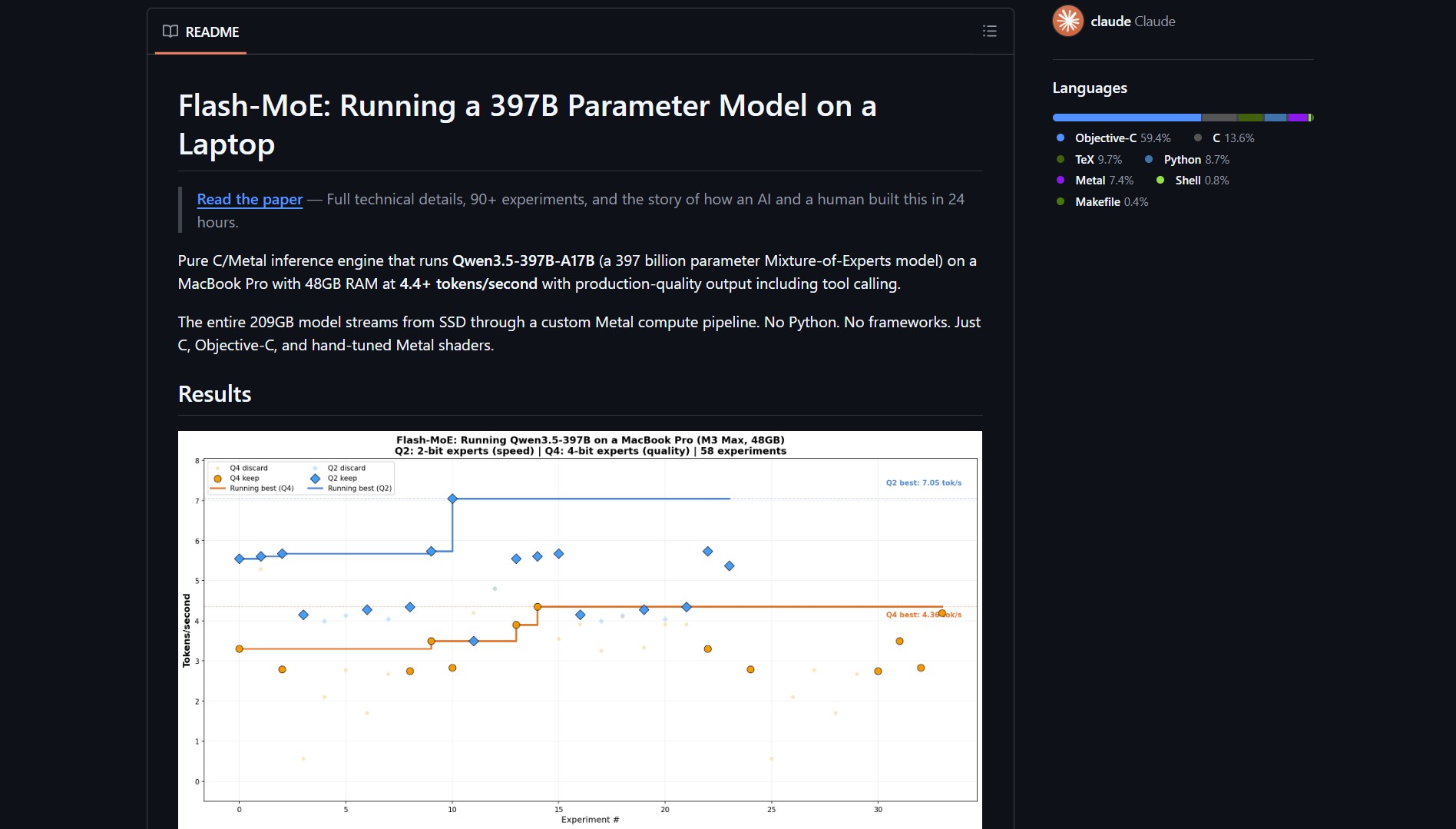
The engine runs on a MacBook Pro with 48GB unified memory and fast SSD bandwidth. It activates only 17B parameters at any time, typical for Mixture-of-Experts models. This makes streaming feasible with consumer hardware.
Community Insights
Community reactions highlight the significance of this approach. One user notes that flash-moe turns memory hierarchy into a product. Another observes that only active parameters need to be loaded, enabling large models on limited RAM.
Flash-moe demonstrates that massive models can run locally by rethinking hardware constraints. It opens new possibilities for on-device AI without data-center-scale infrastructure.
The Verdict
Flash-moe changes the economics of local AI by streaming weights from SSD. It makes 400B-parameter models accessible on consumer hardware. The project shows how deep understanding of Apple Silicon can yield order-of-magnitude improvements. Developers can now experiment with billion-parameter models without cloud costs.
