
BitNet.cpp is Microsoft’s official inference framework for 1-bit LLMs. It enables running very large quantized models on standard CPUs without GPU hardware. The framework provides optimized kernels for lossless inference at 1.58-bit precision using the BitNet b1.58 architecture.
The first release focuses on CPU inference, with GPU and NPU support planned. This lets you run models that previously required expensive GPU clusters on commodity hardware, similar to how you can build a self-hosted offline AI platform for complete local control over inference.
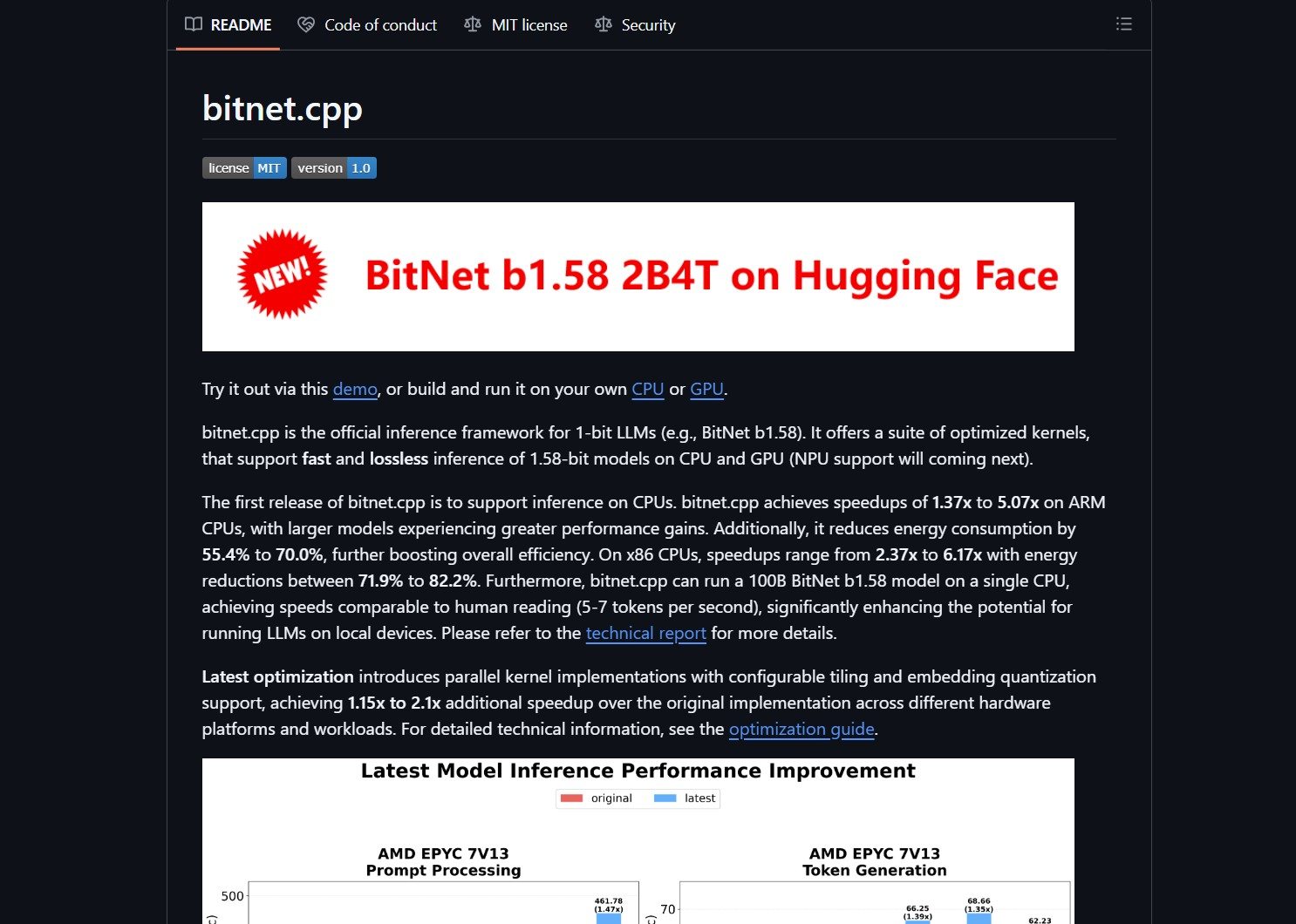
Performance and Tradeoffs
BitNet.cpp delivers significant speedups and energy reductions on CPUs. ARM CPUs see 1.37x to 5.07x inference speedup and 55-70% energy reduction. x86 CPUs see 2.37x to 6.17x speedup and 72-82% energy reduction. The framework claims the ability to run a 100B BitNet b1.58 model on a single CPU at 5-7 tokens per second.
Project link:
https://github.com/microsoft/BitNet
How It Works
BitNet.cpp uses 1.58-bit ternary weights (-1, 0, +1) to dramatically reduce memory and compute requirements. The optimized kernels handle quantization and dequantization efficiently for each supported architecture. You can also run on-device models locally, similar to how you can access Apple’s hidden 3B LLM on your Mac for local inference.
To try it locally, clone the repo and follow the build instructions for your platform. Build optimized kernels and run the tests to verify performance on your hardware.
The Catch
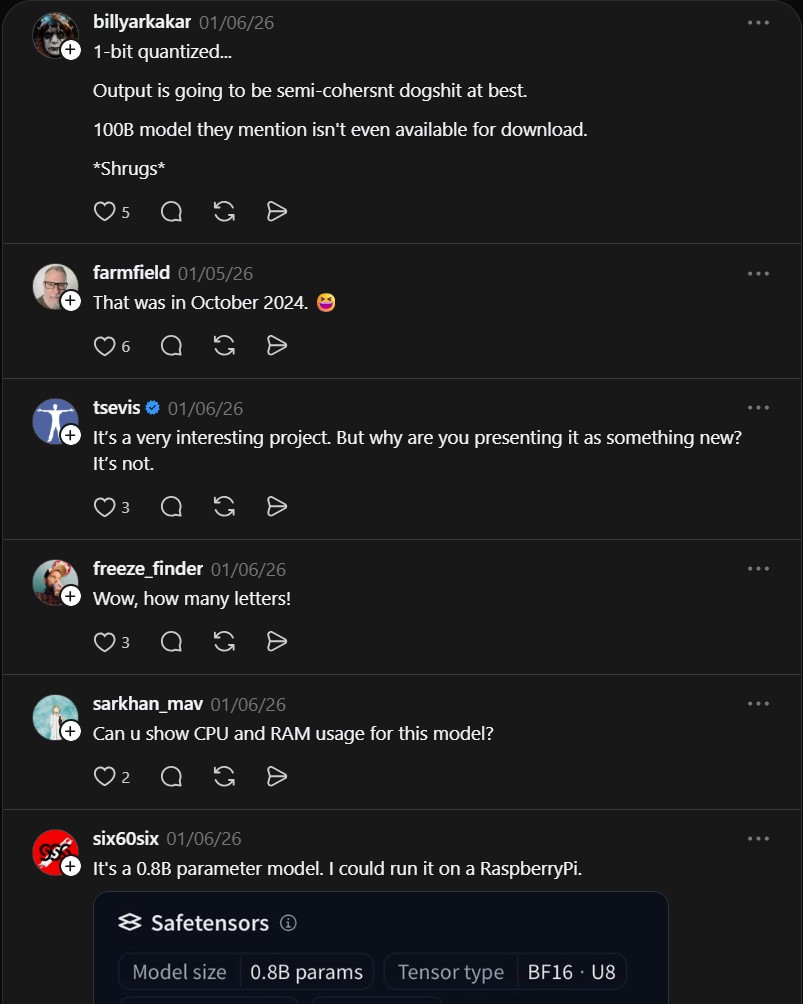
Community responses point out significant discrepancies in the 100B model claims. Critics note the actual available model is closer to 0.8B parameters, not 100B. Output quality at 1-bit quantization is questionable, with some calling it “semi-coherent dogshit at best.” The 100B model mentioned in the paper is not available for download.
The technology is promising for low-power, privacy-preserving local inference. But verify model releases and benchmarks before assuming production readiness. Quantized models trade output quality for speed, so test on your specific use case first.
- PDFCraft, Browser PDF Toolkit for Private Documents
Symphony is an orchestration layer from OpenAI that automates the ticket-to-PR lifecycle. It watches issue trackers like Linear, spawns isolated..
