
Symphony is an orchestration layer from OpenAI that automates the ticket-to-PR lifecycle. It watches issue trackers like Linear, spawns isolated workspaces for new tickets, and assigns autonomous agents to implement features end to end. The goal is to remove the human middleman from routine engineering workflows.
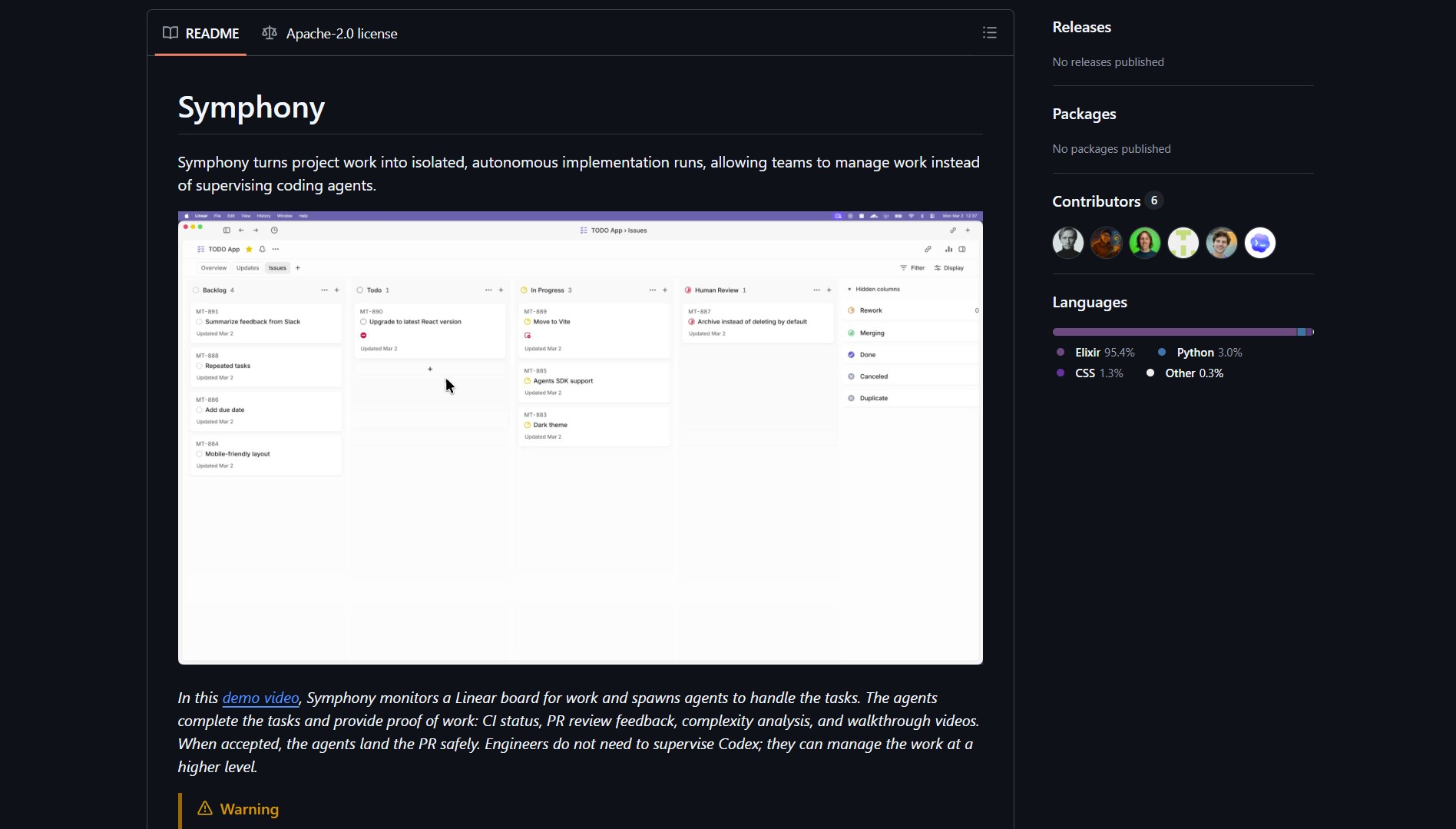
Symphony hooks into Linear and other trackers to detect new tickets in real time. It creates ephemeral environments so each task runs in isolation. The agent writes code, runs tests, opens PRs, responds to review feedback, and generates a walkthrough video. This is similar to how you can use Cline as an AI coding assistant for targeted code generation, but Symphony owns the full lifecycle from ticket to merge.
Project Link
Project link:
https://github.com/openai/symphony
How It Works
Symphony combines four core components. The monitor watches for new tickets. The workspace manager spins up isolated environments. The autonomous agent implements features, runs test suites, and files PRs. The CI integrator gates merges until all checks pass. You can pair Symphony with a self-hosted offline AI platform for teams that need stricter data control over their agent infrastructure.
Start with a restricted pilot on small repos and noncritical branches. Set explicit rollback policies before scaling. Measure flakiness, test coverage, and PR quality to decide whether the agent pipeline is ready for production use. You can also look at Career-Ops for another example of agent-driven workflow automation applied to job searching.
The Catch
Symphony changes the human role from implementer to reviewer and manager of agent behavior. Autonomous development agents carry safety, security, and compliance risks. Run experiments in isolated labs and require human approval for production merges. Keep strong observability, audit logs, and a clear rollback strategy. The practical limit is trust in agent output, so validate everything before landing.
- STFU: Browser Speech Jammer That Shuts Up Loud Talkers
STFU running in the browser with delayed audio feedback controls We have all been there. Stuck at an airport next..
