
Developers working with AI coding assistants are increasingly running into a familiar wall: context loss. As chat sessions grow longer, models drift, forget project structure, or produce inconsistent outputs, a problem that compounds quickly on anything beyond simple, single-file tasks.
A GitHub project called Superpowers is gaining quiet traction as a structural fix, enforcing persistent project files and shared specs to keep AI behavior stable across sessions. The approach is model-agnostic, but community discussion has largely centered around pairing it with lighter, faster models to sidestep the context ceiling entirely.
Repo: Superpowers GitHub
The core insight behind the workflow is that context degradation isn’t just a model problem, it’s a session management problem. By externalizing project state into persistent files rather than relying on what the model can hold in memory, developers report being able to switch chat sessions freely without losing continuity or confusing the AI.
In practice, users running Gemini 3.0 Flash in Fast mode through Antigravity report never losing context mid-task, with session changes remaining safe and predictable. More capable models like Sonnet 4.6 or Gemini 3.1 are reserved selectively for logic-heavy work requiring precise calculations, not as the default workhorse.
Community reactions reflect a mix of hard-won stability and ongoing rough edges.
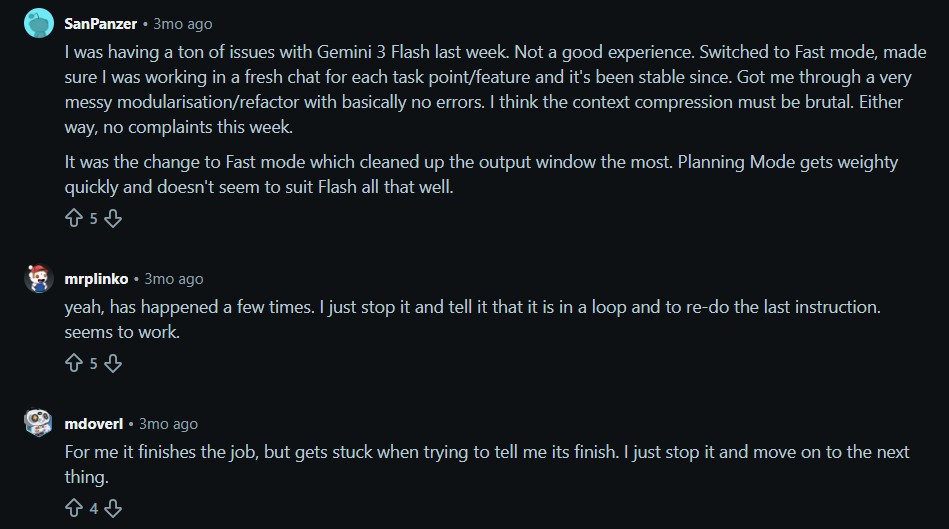
“I was having a ton of issues with Gemini 3 Flash last week. Not a good experience. Switched to Fast mode, made sure I was working in a fresh chat for each task point/feature and it’s been stable since. Got me through a very messy modularisation/refactor with basically no errors. I think the context compression must be brutal. Either way, no complaints this week. It was the change to Fast mode which cleaned up the output window the most. Planning Mode gets weighty quickly and doesn’t seem to suit Flash all that well.”
said u/SanPanzer
“For me it finishes the job, but gets stuck when trying to tell me its finish. I just stop it and move on to the next thing.”
said u/mdoverl
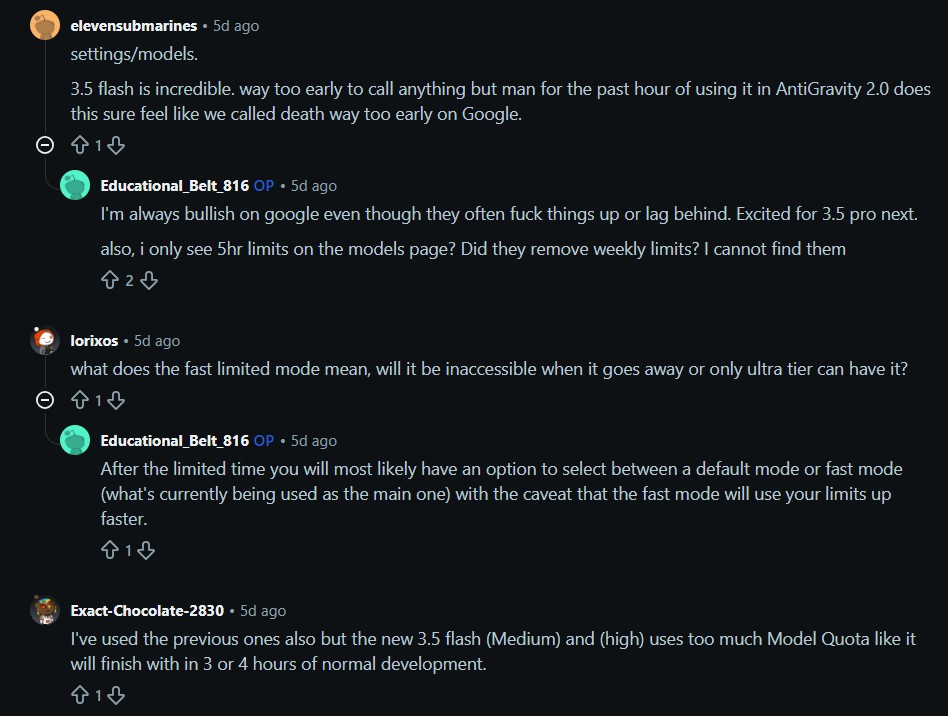
“settings/models. 3.5 flash is incredible. way too early to call anything but man for the past hour of using it in AntiGravity 2.0 does this sure feel like we called death way too early on Google.”
said u/elevensubmarines
The emerging pattern among users is deliberate model tiering, lean on fast, cheap models for the bulk of session work, keep context windows clean by starting fresh per task, and only escalate to heavier models when the problem genuinely demands it. It’s less about finding a single best model and more about structuring the workflow so no model ever has to do more than it’s good at.
