A developer going by h4ckf0r0day just shipped one of the most consequential infrastructure releases for AI agents in 2026, and the project is the first credible open source challenge to headless Chrome in the scraping and automation space.
The repository is called Obscura, and it is a Rust based browser built specifically for AI agents and web scraping. It works as a drop in replacement for Puppeteer and Playwright, which means existing automation code can swap over with minimal changes, and the performance numbers are the kind of improvement that changes how people architect agent systems.
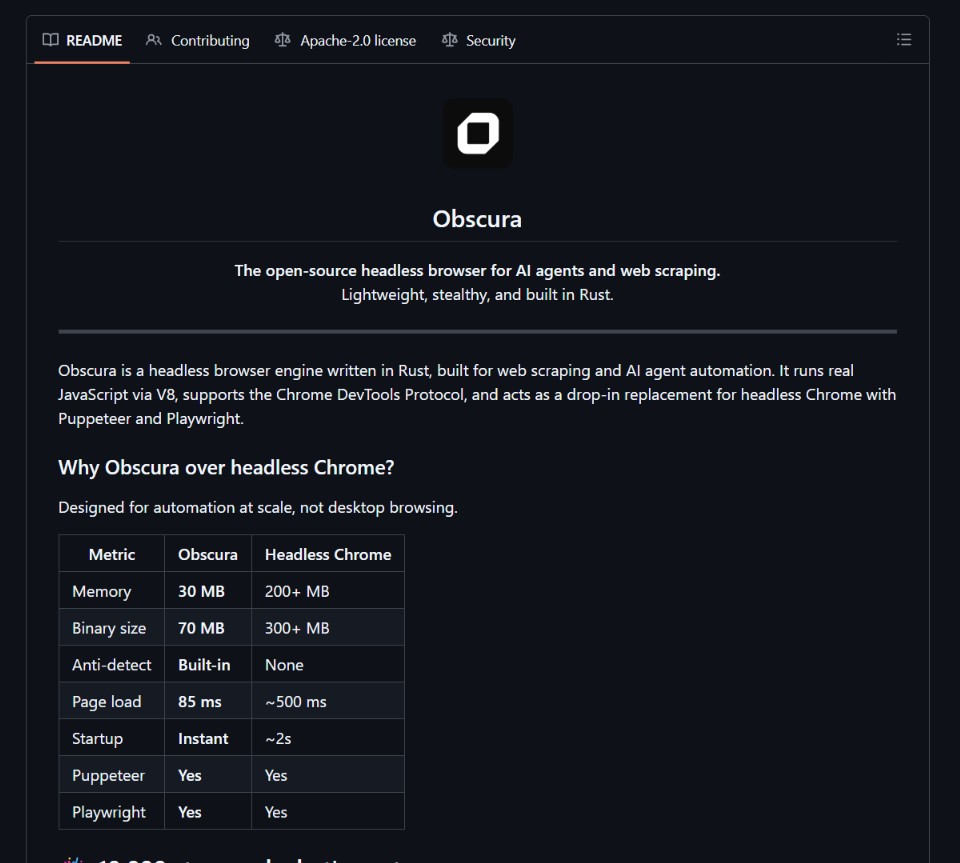
The headline comparison tells the story. Chrome headless consumes 200MB or more of RAM per instance. Obscura uses 30MB. Chrome headless takes around 500 milliseconds to load a page. Obscura does it in 85 milliseconds. Obscura blocks 3,520 trackers by default and ships with anti detection built in. The whole thing is a single binary. It is 100 percent open source.
This is not an incremental improvement. It is the missing infrastructure layer the AI agent ecosystem has been waiting for.
The Problem Most Browser Automation Stacks Leave on the Floor
The current state of browser automation in 2026 is held together by duct tape and headless Chrome, and the cracks are showing. Most AI agent and scraping pipelines run on Puppeteer, Playwright, or Selenium, all of which ultimately drive a real Chromium instance underneath.
- Memory usage scales linearly with concurrency: every parallel agent or scraper pays the Chrome RAM tax, which kills cost economics at scale
- Startup time is slow: 500ms per page load is fine for human browsing but expensive when an agent does it thousands of times per hour
- Detection is a constant battle: Chrome has a fingerprint that anti bot systems recognize instantly, and bypassing it requires extra tools
- Tracker bloat slows everything down: every page load pulls in analytics, ad pixels, and tracking scripts that the automation does not need
- Operational overhead is real: running dozens of headless Chrome instances means managing zombie processes, memory leaks, and crashes
Obscura is built to solve all five of these problems at the browser layer rather than patching around them, and that is why the infrastructure community is paying attention.

What is Actually in the Repository
The repo ships a working Rust browser with a focused feature set rather than trying to be a general purpose browser.
- Rust Core: The browser is implemented in Rust for memory safety, low overhead, and fast startup, which gives it the performance profile Chrome can never match
- Puppeteer and Playwright Compatibility: The automation protocol layer is designed to be a drop in replacement, so existing scripts written against Puppeteer or Playwright can switch over with minimal refactor
- Built in Anti Detection: The browser ships with anti bot bypass features built into the default configuration, which removes the need for separate stealth plugins
- Tracker Blocking by Default: 3,520 trackers are blocked out of the box, which speeds up page loads and reduces noise in scraped data
- Single Binary Distribution: The whole browser ships as a single binary, which simplifies deployment, containerization, and edge runtime integration
- Low Memory Footprint: 30MB of RAM per instance means a single server can run 6 to 10 times as many concurrent agents as the same server running headless Chrome
This is the kind of project that does one thing exceptionally well rather than many things adequately, and that focus is what makes it valuable.
Who This is for
The audience for Obscura is the AI agent and scraping community, which has been underserved by the browser layer for a long time.
- AI Agent Developers: Anyone building autonomous agents that browse the web will see immediate cost and performance gains from swapping Chrome for Obscura
- Web Scraping Engineers: Teams running production scraping pipelines at scale will benefit most from the lower memory, faster loads, and built in anti detection
- Browser Automation Developers: Engineers building Playwright or Puppeteer workflows can migrate with minimal code changes and gain performance for free
- Data Extraction Teams: Analytics and research teams that scrape large datasets benefit from faster loads, fewer blocked requests, and lower infrastructure cost
- Infrastructure Engineers: DevOps and platform teams running scraping or agent fleets can replace dozens of Chrome instances with a fraction of the resource footprint
If you have ever paid a large cloud bill for headless Chrome instances, Obscura is built for you.
What People are Saying

The early reaction from the AI agent infrastructure community captures both the technical value and the strategic significance.
“this is a big deal for ai agent infrastructure. chrome was never designed for automation at scale, it was built for human browsing. obscura being purpose-built for agents means better performance, lower resource usage, and fewer detection issues. the 30MB vs 200mb ram difference alone is massive for running multiple agents”
@vikivirgon
The reaction is the right one. Chrome was built for humans, not for fleets of agents, and forcing agents to run inside a human browser has always been a workaround. Obscura flips that around and builds the browser for the actual user, which is the agent.
The 30MB versus 200MB comparison is not a benchmark number. It is an economic number. A server that could run 5 Chrome instances can now run 30 Obscura instances, and that is the difference between an unprofitable scraping product and a profitable one.
Why This Repo Matters for the AI Agent Ecosystem
The bigger story is not the browser itself. It is what becomes possible when the browser layer stops being a bottleneck.
- Agent Cost Drops by an Order of Magnitude: Memory and CPU are the two biggest costs in agent infrastructure. Obscura cuts both, which changes the unit economics of running agents at scale
- Scraping Reliability Improves: Built in anti detection and tracker blocking reduce the failure rate on real world scraping targets, which improves data quality across the pipeline
- Edge Deployment Becomes Real: A 30MB binary that loads pages in 85ms can run on edge devices, small VPS instances, and constrained environments where Chrome was never viable
- The Stack Simplifies: Replacing Chrome plus a stealth plugin plus a tracker blocker plus a memory monitor with a single binary reduces the moving parts in any agent or scraping pipeline
- Open Source Beats Vendor Lock In: The browser is open source, so the AI agent ecosystem owns the infrastructure rather than depending on Chrome and the Chromium team’s roadmap
Repo: https://github.com/h4ckf0r0day/obscura
Obscura is the open source infrastructure release that the AI agent and scraping communities have been waiting for since headless Chrome became the default. The project is not flashy, but it is exactly what the ecosystem needs in 2026, which is a browser built for agents rather than humans, with the performance and cost profile that agent workloads actually require.
Anyone running Puppeteer, Playwright, or headless Chrome in production should clone the repo, run the benchmarks on their own workload, and plan the migration. The 30MB versus 200MB number alone is enough to justify the switch. Chrome was the right answer for human browsing in 2008. Obscura is the right answer for agent browsing in 2026.
