A developer and educator going by rasbt just dropped the definitive open source guide to building a GPT style language model from zero, and the project is the cleanest pedagogical resource on transformers available anywhere in 2026.
The repository is called LLMs-from-scratch, and the entire premise is that you learn how an LLM works by building one yourself with pure PyTorch. No external libraries. No hidden APIs. No black box wrappers. The transformer, the tokenizer, and the training loop are all implemented from first principles in code you can read line by line.
This sounds like a textbook. It is not. It is a working GitHub repository that takes you from empty file to trained model, and the value of walking that path is hard to overstate. Anyone who has used ChatGPT, Claude, or any modern LLM through an API has experienced the output. Almost nobody has understood the mechanics. LLMs-from-scratch closes that gap.
The Problem Most AI Tutorials Leave on the Floor
The current state of AI education has a strange gap at the foundation. Most tutorials start at the wrong layer. They assume you will call `model.fit()` or `pipeline.generate()`, and they treat the transformer as a black box. That approach gets you productive fast, but it leaves you unable to answer the questions that actually matter when you build real systems.
Why does the tokenizer behave the way it does on edge cases?
What is happening to the weights during a single training step?
Why does fine tuning on a small dataset sometimes destroy general capability?
Where does the model’s context window actually come from?
LLMs-from-scratch is built to answer those questions, and the way it answers them is by making you implement the parts yourself. You do not import a transformer. You write the attention mechanism. You do not call a tokenizer library. You build the byte pair encoder. You do not use a training framework. You write the loop. By the time you finish, you understand the system, and that understanding is what separates an AI engineer from an AI user.

What is Actually in the Repository
The repo walks the full pipeline of a GPT style model, and each stage is implemented in clean PyTorch with explanatory notebooks alongside the code.
- Tokenization from Scratch: The book implements a byte pair encoding tokenizer rather than calling an existing one. You learn how text becomes integers and why the vocabulary size is a tradeoff.
- Transformer Architecture: The full transformer is built layer by layer. Attention, multi head attention, positional encoding, layer normalization, and the residual connections are all written out explicitly.
- Training Loop: The training loop is implemented from scratch, including the data loader, batching, the forward pass, the loss calculation, and the optimizer step. You see the gradient update happen.
- Fine Tuning and Inference: The guide extends into instruction fine tuning and inference patterns, so the model you build is not just a research toy. It can be aligned and deployed.
This is the rare resource that respects the reader enough to teach the hard parts rather than abstract them away.
Who This is for
The audience for LLMs-from-scratch is not beginners, and it is also not researchers who already work on architectures. It is the people in between, the ones who need to deeply understand how the systems they use every day are actually constructed.
- AI Engineers: Anyone shipping LLM features into production will debug, optimize, and customize those systems. That work is impossible without a first principles understanding, and this is the fastest path to it.
- Machine Learning Students: University courses often skip the implementation details because of time constraints. This repo fills in what the curriculum leaves out.
- Researchers: Researchers coming from adjacent fields (computer vision, classical NLP, reinforcement learning) often need a concrete reference implementation to translate their intuition into transformer language.
- Educators: Teachers who run bootcamps, workshops, or self guided study programs can use the repo as a curriculum backbone.
- Developers: Anyone who has called an LLM API and wondered what is actually happening on the server will find the answer here.
If you have ever felt that you understand what an LLM does but not how it does it, this repo is for you.
What People are Saying
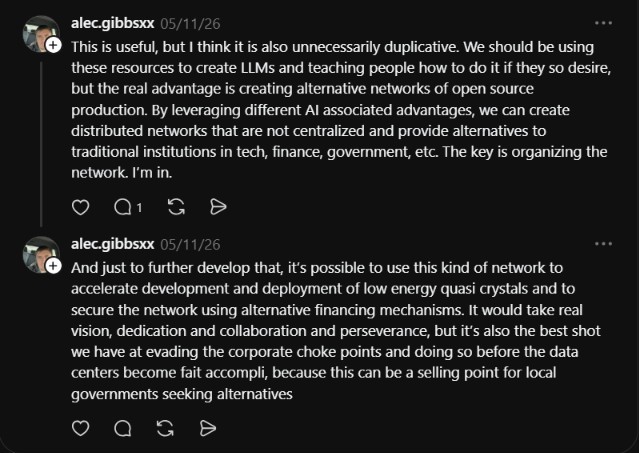
The early reaction captures both the value of the resource and the broader question of where to spend effort in open AI.
“This is useful, but I think it is also unnecessarily duplicative. We should be using these resources to create LLMs and teaching people how to do it if they so desire, but the real advantage is creating alternative networks of open source production. By leveraging different AI associated advantages, we can create distributed networks that are not centralized and provide alternatives to traditional institutions in tech, finance, government, etc. The key is organizing the network. I’m in.”
@alec.gibbsxx
The reaction splits into two parts. The first half is appreciation for the educational value of the repo. The second half pushes the conversation forward into distributed open source networks and non centralized alternatives. That second half is the meta question the open AI community is increasingly asking, which is whether teaching people to build is the right goal, or whether the next step is teaching people to organize.
Why this Repo Matters for the AI Engineering Field
The bigger story is not the GitHub stars. It is the kind of engineer this resource produces.
- First Principles Engineers Are the Scarce Resource: The market is full of API wrappers. The market is short on engineers who can debug a transformer at the layer level. This repo closes that gap.
- Open Source Beats Vendor Lock In: A community that understands transformers from first principles is harder to lock into a single vendor’s abstraction layer. That is good for the field.
- Teaching Beats Black Boxing: The next wave of AI capability will come from people who can extend and modify architectures rather than just call them. The repo is a training ground for that kind of work.
- The Pipeline Is Now Reproducible: A graduate, a researcher, or an engineer in any country with internet access can read this repo and reproduce a working GPT style model. That reproducibility is the foundation of a healthy open AI ecosystem.
Repo: https://github.com/rasbt/LLMs-from-scratch
LLMs-from-scratch is the rare open source project that improves the entire AI engineering field rather than just one product. The repository is not flashy, but it is exactly what the AI industry needs in 2026, which is a rigorous, first principles teaching resource that treats the reader like an engineer rather than a consumer.
Anyone who wants to move from calling AI APIs to actually building AI systems should work through this repo cover to cover. The effort is real, but the capability you walk away with is the capability that defines the next generation of AI builders. The transformers are not magic. LLMs-from-scratch proves it by handing you the source code, and that is the most useful thing an open source AI project can do in 2026.
